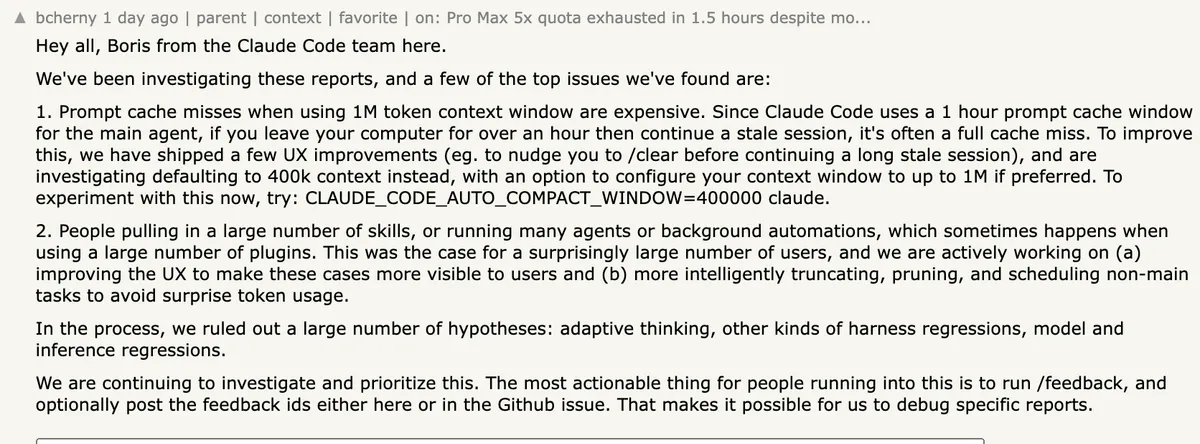
 Screenshot of Boris Cherny's comment on Hacker News
Screenshot of Boris Cherny's comment on Hacker News Anthropic Finally Explains Why Claude Code Has Been Burning Through Quotas
Boris Cherny, creator of Claude Code, pins a Discord message identifying two root causes behind weeks of user complaints about rapid quota drain. The 1M context window and runaway plugins are the culprits.
After three weeks of escalating complaints from developers across Reddit, GitHub, Hacker News, and X, Anthropic’s Boris Cherny has posted a detailed explanation of what’s actually causing Claude Code to chew through usage quotas at alarming rates.
Cherny, the creator of Claude Code, pinned a message in the official Discord server on April 13 laying out the team’s investigation findings. The short version: the 1M token context window is silently expensive when cache misses happen, and a surprising number of users are running skills and plugins that spawn background agents consuming tokens they don’t see.
Two Root Causes
The first issue is prompt cache misses on the 1M context window. Claude Code uses a 1-hour prompt cache for its main agent. If you step away from your computer for more than an hour and then pick up where you left off, you’re likely hitting a full cache miss. On a 1M context window, that means the entire conversation context gets reprocessed at the cache creation rate, which costs roughly 12.5x more than reading from cache.
To put that in practical terms: a session with 500k tokens of context that hits a cache miss costs the same as roughly 12 cache-hit sessions of the same size. Users who habitually leave sessions open overnight or over lunch breaks, then continue working in the same session, were unknowingly paying this penalty every time.
Cherny’s team has already shipped UX improvements that nudge users to run /clear before continuing a stale session. They’re also investigating a more significant change: defaulting the context window to 400k tokens instead of 1M, with an option to configure it higher. Users who want to test this now can set an environment variable:
CLAUDE_CODE_AUTO_COMPACT_WINDOW=400000 claudeThis tells Claude Code to treat its context window as 400k tokens for auto-compaction purposes, triggering context summarization earlier and keeping the active window smaller.
The second issue is runaway skills, agents, and plugins. A “surprisingly large number of users,” as Cherny put it, were running many agents or background automations through plugins without realizing the token cost. Each skill, background agent, or automation spawned by a plugin consumes tokens independently, and until now the UX did a poor job of making that consumption visible.
The team is working on two fixes: making these background costs visible in the interface, and building smarter truncation, pruning, and scheduling for non-main tasks so they don’t silently eat through quotas.
What They Ruled Out
Cherny explicitly addressed several theories that had been circulating in the community. The team investigated and ruled out:
- Adaptive thinking as a cause of excess token consumption
- Harness regressions (bugs in how Claude Code manages the model interaction layer)
- Model and inference regressions (the model itself getting worse or more expensive)
This is notable because all three of these were popular theories in GitHub issues and community threads. Users had been filing detailed reports speculating that Anthropic had quietly changed how adaptive thinking worked, or that a harness update had broken caching, or that the underlying model was generating more tokens than before. According to Cherny’s investigation, none of those were the problem.
The Broader Context
This investigation didn’t happen in a vacuum. The complaints started around March 23, 2026, and snowballed quickly. Users across all paid tiers, from Pro ($20/month) to Max 20x ($200/month), reported that sessions which previously lasted a full workday were exhausting in under two hours. Some Max 20x subscribers reported hitting 100% quota drain in 70 minutes.
The frustration spawned a cascade of GitHub issues. Issue #41930, titled “Critical: Widespread abnormal usage limit drain across all paid tiers since March 23, 2026,” became a central tracking thread with dozens of user reports. Issue #46829 included analysis of over 119,000 API calls and documented what the filer estimated as hundreds of dollars in overpayment due to cache behavior. Issue #34629 demonstrated a roughly 20x cost increase per message when using the --print --resume flags.
Independent researchers dug into the problem from the outside. After Claude Code’s source code was accidentally exposed via an npm source map file on March 31, community members reverse-engineered the caching behavior and identified additional bugs beyond what Anthropic’s own investigation surfaced. A comprehensive analysis documented 11 confirmed bugs across 30,000+ requests and 230 sessions, including a sentinel string replacement issue that could break cache prefixes and a resume flag that invalidated entire conversation caches.
The story picked up mainstream tech press coverage from The Register, MacRumors, The New Stack, and DevOps.com.
What This Means Going Forward
The most immediate takeaway for Claude Code users: if you’re on the 1M context tier, consider setting CLAUDE_CODE_AUTO_COMPACT_WINDOW=400000 until Anthropic changes the default. Start new sessions with /clear when returning after breaks. And audit your plugins and skills, because each one might be spawning background work that counts against your quota.
The larger question is whether subscription-based AI coding tools can sustain the “unlimited use” mental model that developers have come to expect. Claude Code’s pricing tiers advertise usage limits in vague terms (“5x” or “20x” relative to Pro), and the actual token math behind those limits is opaque. When a single cache miss can cost 12x a normal interaction, the gap between perceived and actual consumption gets wide fast.
Cherny’s sign-off in the Discord post pointed users toward /feedback and invited them to post their feedback IDs for debugging. The investigation is ongoing. But at least now there’s a public explanation for what went wrong, which is more than users had for the previous three weeks.
Sources:
- Boris Cherny, pinned Discord message in Claude Code server, April 13, 2026
- Boris Cherny, Hacker News comment (item #47740541)
- The Register: Anthropic: Claude quota drain not caused by cache tweaks (April 13, 2026)
- The Register: Anthropic admits Claude Code quotas running out too fast (March 31, 2026)
- GitHub Issue #41930: Critical widespread abnormal usage limit drain
- GitHub Issue #46829: Cache TTL silently regressed
- GitHub Issue #34629: Prompt cache regression in —print —resume
- ArkNill/claude-code-hidden-problem-analysis (cache bug analysis)
- MacRumors: Claude Code Users Report Rapid Rate Limit Drain
- The New Stack: Claude Code users hitting usage limits faster than normal
- Claude Code documentation: Environment variables