 JetBrains / Hugging Face
JetBrains / Hugging Face JetBrains Open-Sources Mellum2, a 12B MoE Model Built for AI Coding Workflows
JetBrains released Mellum2 under Apache 2.0 on June 1. It's a 12B parameter mixture-of-experts model with only 2.5B active per token, designed for the repetitive, latency-sensitive tasks inside AI coding pipelines: routing, RAG, sub-agents, and tool use.
JetBrains published Mellum2 on Hugging Face on June 1, 2026. The technical report was posted to arXiv two days earlier. The license is Apache 2.0.
The model is 12 billion parameters total, but the architecture is Mixture-of-Experts: only 2.5 billion parameters are active on any given token. There are 64 experts, 8 activated per forward pass. This is the same tradeoff you see in Mistral’s Mixtral and DeepSeek’s MoE releases, trading total parameter count for faster inference at lower compute cost.
JetBrains released three variants: Base, Instruct, and Thinking. The Instruct model is the one built for agent pipelines. The Thinking model adds explicit <think>...</think> reasoning blocks for harder tasks.
Why Mellum2 Exists
The framing from JetBrains is worth reading directly: “Modern AI systems increasingly rely on multiple model calls: routing, retrieval, summarization, planning, validation, and tool use. Many of these operations are latency-sensitive and do not require the largest available model.”
That’s the pitch. Mellum2 is not trying to beat Claude or GPT on frontier evals. It’s positioned as a “focal model” for the high-frequency, repetitive operations in an AI coding pipeline where you don’t want to be burning frontier model tokens on every intermediate step.
The context window is 128K tokens. Attention uses Grouped-Query Attention (32 Q heads, 4 KV heads) with Sliding Window Attention on 75% of layers, which keeps memory requirements low during long-context inference. The model was trained on roughly 10.6 trillion tokens in a three-phase curriculum: general web data first, then code and math.
Benchmark Numbers
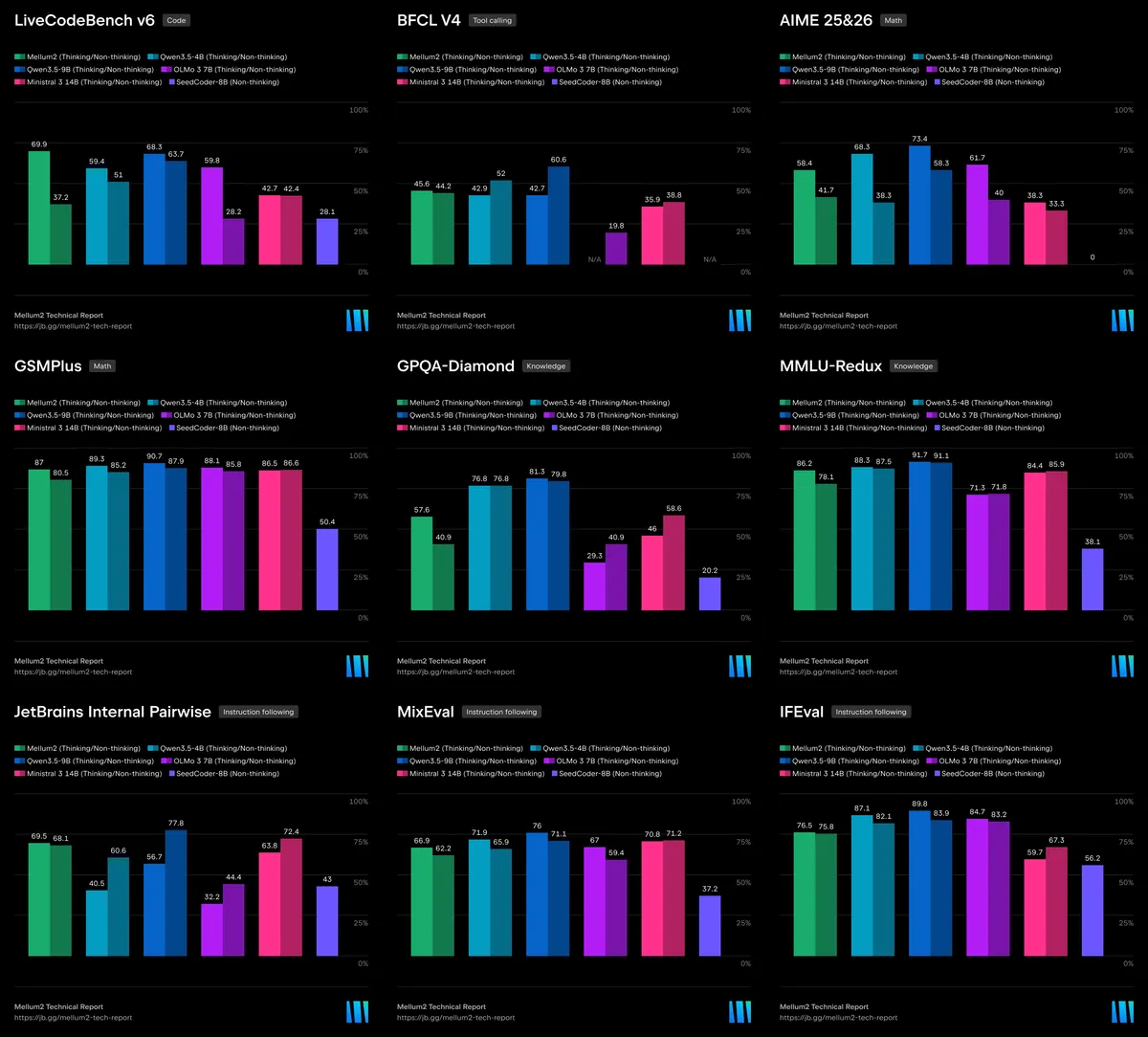
The Instruct model (the practical “deploy this in your agent” variant) scored:
- LiveCodeBench v6: 37.2%
- EvalPlus: 78.4%
- MultiPL-E: 67.1%
- BFCL v3 (function calling): 66.3%
- AIME 2025+2026: 41.7%
- GPQA Diamond: 40.9%
- MMLU-Redux: 78.1%
The Thinking variant scored substantially higher on reasoning benchmarks: LiveCodeBench v6 at 69.9%, AIME at 58.4%, GPQA Diamond at 57.6%. It’s a different use case, though. The Thinking model is for when you actually need the chain-of-thought, not for the fast routing call you’re making 50 times per task.
JetBrains compared Mellum2 against Qwen3.5 4B, Qwen3.5 9B, OLMo-3 7B, Ministral 3 14B, and Seed-Coder 8B in their evaluations. Mellum2-Instruct’s 78.4% on EvalPlus, for example, beats Ministral 3 14B’s 74.1% despite having fewer active parameters.
JetBrains claims “more than 2x faster inference” compared to similarly sized models, which the MoE design makes plausible but which you’d want to benchmark against your specific hardware before taking at face value.
What You’d Actually Use This For
If you’re building an AI coding pipeline with multiple steps, the expensive frontier models are probably not running on every step. You route, you classify, you check tool outputs, you summarize context windows. For those operations, you want something fast, cheap, and reasonably capable.
Mellum2 fits that slot. It’s not going to replace your frontier model for the hard reasoning step. But if you’re paying frontier rates for routing calls, you’re probably overpaying.
You can pull the model directly from Hugging Face: JetBrains/Mellum2-12B-A2.5B-Instruct and JetBrains/Mellum2-12B-A2.5B-Thinking. The Apache 2.0 license means you can run it locally, self-host it, or build commercial products with it without restriction.
The full technical report is at arxiv.org/abs/2605.31268.