 Anthropic
Anthropic Anthropic Releases Claude Fable 5, Its First Public Mythos-Class Model
On June 9, 2026, Anthropic made a Mythos-class model generally available for the first time. Claude Fable 5 tops frontier coding benchmarks, ships at $10/$50 per million tokens, and routes its most dangerous capabilities to an older model through new safeguards. Here is what launched, what the benchmarks show, and how the safety system works.
Anthropic released Claude Fable 5 today, the first time a model from its Mythos line has been put in front of the general public. Until now, Mythos lived behind a restricted program. Fable 5 is the version Anthropic decided was safe enough to ship to anyone with a paid plan or an API key.
The company is blunt about what it has built. “Fable 5’s capabilities exceed those of any model we’ve ever made generally available,” the announcement reads. That claim lands a little differently given the context. Anthropic spent the spring warning that Mythos-class systems were getting dangerous enough to keep on a tight leash. Releasing one publicly is the company arguing it has figured out how to hand over the capability while holding back the parts that scared it.
Two models, one set of weights
There are two releases. Claude Fable 5 (API name claude-fable-5) is the public model. Claude Mythos 5 is the same underlying model with some of the safeguards removed, and it is not going to most customers. Anthropic is routing Mythos 5 to a small group of cyberdefenders and infrastructure providers through Project Glasswing, its restricted-access program run in collaboration with the US government.
So the difference between the model you can buy and the model the government partners get is not the weights. It is the guardrails. That distinction sits at the center of the whole release.
Both cost the same: $10 per million input tokens and $50 per million output tokens. That is roughly double the rate of Claude Opus 4.8, which makes Fable 5 the most expensive model Anthropic has shipped. It is also, by the company’s framing, less than half the price of the earlier Claude Mythos Preview, so the trend on Mythos-class pricing is down even as the capability climbs.
The benchmarks
Fable 5 is state of the art on nearly every public benchmark Anthropic tested, with the largest leads showing up on long, agentic coding work.
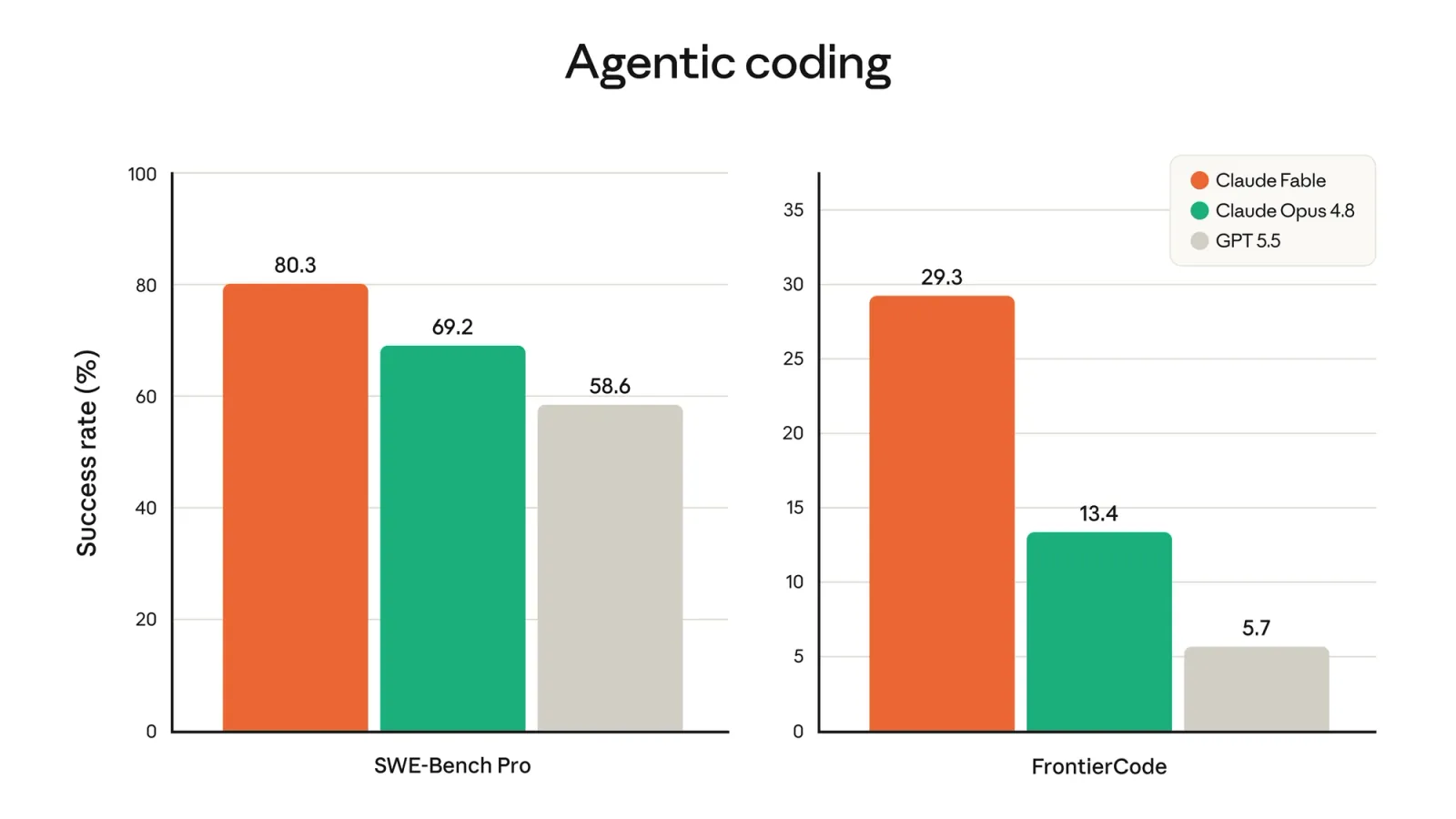
On SWE-Bench Pro, Fable 5 hit 80.3% against 69.2% for Opus 4.8 and 58.6% for GPT 5.5. The gap widens on Cognition’s FrontierCode, where Fable scored 29.3% while Opus managed 13.4% and GPT 5.5 reached 5.7%. The pattern Anthropic keeps pointing to is that the lead grows with the length of the task: “The longer and more complex the task, the larger Fable 5’s lead over our other models.”
The partner numbers back that up. Hex says Fable was the first model to break 90% on its analytics benchmark of complex, long-running analytical tasks, a roughly 10-point jump over the previous Opus-class result. Cursor calls it state of the art on CursorBench, with its CEO quoted saying Fable “opened up a class of long-horizon problems that were out of reach.” One migration cited in the launch took a 50-million-line Ruby codebase and moved it in a day, work the company estimates would have taken two months by hand.
Vision and research get the same treatment. Anthropic describes Fable extracting numbers from scientific figures, rebuilding working web apps from a screenshot, and, in the kind of demo that has become a tradition, beating Pokémon FireRed using vision alone. On the science side it says a blind comparison had researchers preferring the model’s molecular biology hypotheses about 80% of the time over an Opus-class model.
The safeguards are the actual product
What makes a public Mythos release possible is not the capability. It is the system Anthropic built to withhold part of it. Fable 5 ships with classifiers that watch for three categories of request: cybersecurity (specifically exploitation and offensive cyber work), biology and chemistry with dual-use risk, and distillation, meaning attempts to extract the model’s capabilities to train another model.
When a request trips one of those classifiers, Fable 5 does not refuse outright. It hands the response off to Claude Opus 4.8, the older and less capable model. You still get an answer. You just get it from a model that cannot do the dangerous version of the task.
Anthropic says this fallback fires in less than 5% of sessions, and that more than 95% of Fable sessions run entirely on Fable’s own responses. The company also admits the dial is turned conservative: “we’ve deliberately tuned the safeguards to be cautious, and they are still stricter than would be ideal,” and benign requests will sometimes trip the classifiers. It plans to loosen the false positives after launch.
The offensive cyber chart is the clearest picture of the safeguards at work.
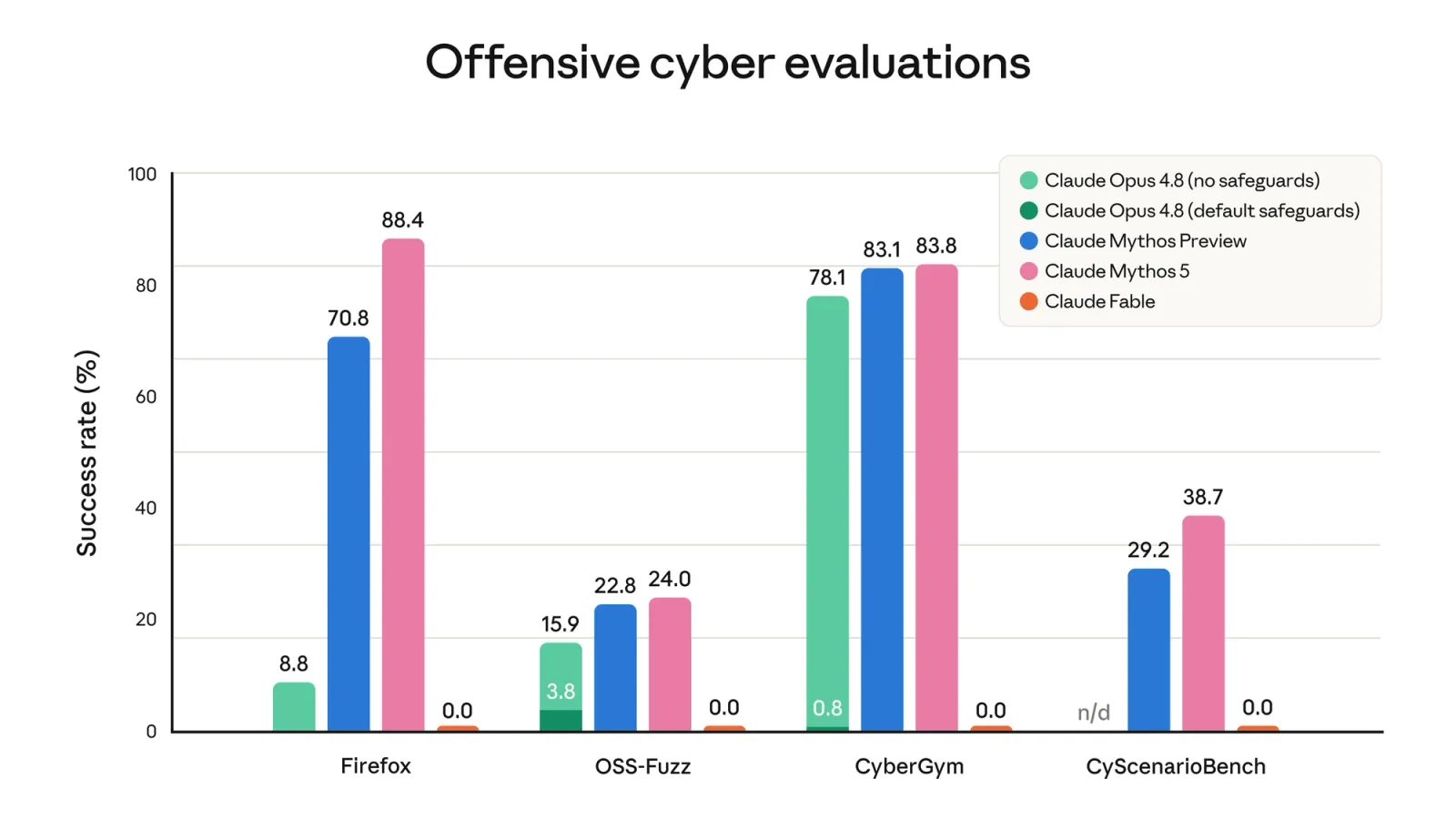
Read that chart from the orange bars. On Firefox exploitation, OSS-Fuzz, CyberGym, and CyScenarioBench, the unrestricted Mythos 5 posts some of the highest scores Anthropic has ever reported, up to 88.4% on Firefox. Claude Fable, the public model, sits at 0.0 on all four. The safeguard does not just reduce the capability. It zeroes it out for the offensive cyber category. Anthropic’s own measurements put the vulnerability-reproduction rate at roughly 1% with safeguards on, against nearly 80% with them off.
To stress the system, the company ran an external bug bounty: more than 1,000 hours of red-teaming that, it says, produced no universal jailbreaks. It does note one caveat, that the UK AI Safety Institute made progress toward a jailbreak in a brief testing window. Every Mythos-class request also carries a 30-day mandatory retention requirement for security monitoring, data Anthropic says it does not train on and aligns with a White House executive order.
Aligned, by the numbers
Anthropic published alignment evaluations alongside the capability ones, and the headline is that scaling to a Mythos-class model did not make behavior worse.
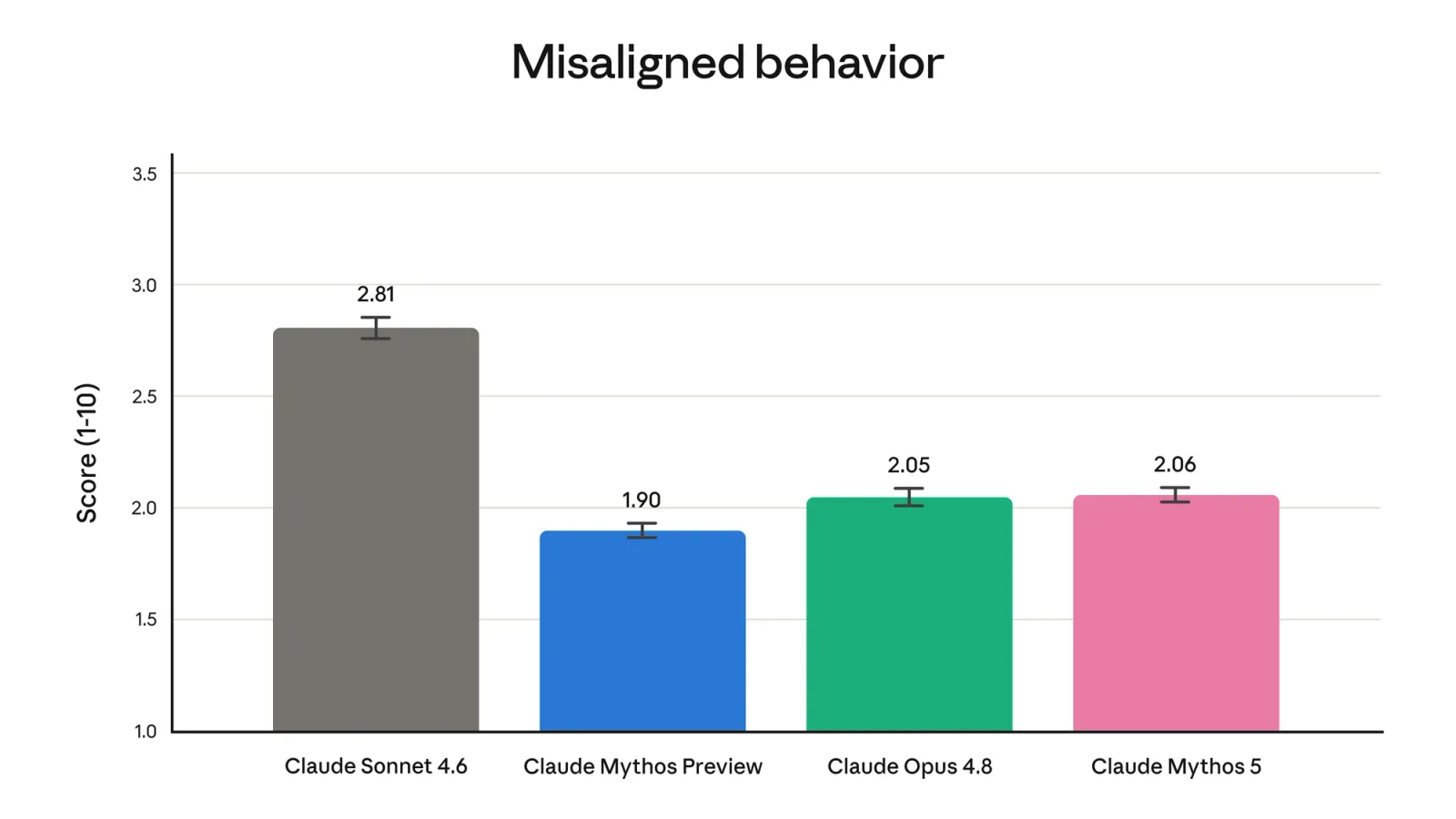
On the misaligned-behavior metric, where a lower score is better, Mythos 5 came in at 2.06, almost identical to Opus 4.8 at 2.05 and well below Sonnet 4.6 at 2.81. The takeaway Anthropic is drawing is that the new model is more capable without being measurably more deceptive or more willing to cooperate with misuse than the model it sits above.
How to get it, and for how long
Fable 5 is available now through the API and to enterprise customers on consumption pricing. For subscribers, the rollout has a deadline attached. From today through June 22, Fable 5 is included at no extra cost on Pro, Max, Team, and seat-based Enterprise plans. On June 23 it comes off those plans and moves to usage credits only, with Anthropic saying it intends to fold the model back into standard plans once it has the capacity. If you are on a paid plan and want to try the model without metering, the next two weeks are the window.
Mythos 5 stays restricted. Project Glasswing partners can step up to it with the cyber safeguards lifted, and Anthropic says it is planning a separate program for select life-science researchers that lifts the biology and chemistry restrictions while keeping the cyber ones in place. The company also said Glasswing has grown to around 150 organizations across more than 15 countries.
Why this one matters
The story here is not only that Anthropic shipped its strongest model. It is that the company drew a hard line through the middle of a single set of weights and decided which side the public gets. Fable 5 is the capable side with the offensive edges filed off, and the benchmarks suggest the filing is real, not cosmetic, at least for the categories Anthropic chose to block. Whether the line holds is the open question, and the company is honest that a brief external test already chipped at it.
For developers, the practical read is simpler. The best agentic coding model on the market right now is one you can call today, it costs about twice what Opus does, and for the next two weeks a chunk of it is free if you already pay for a plan.
Sources
- Claude Fable 5 and Claude Mythos 5 — Anthropic
- Anthropic released Claude Fable 5, its most powerful model publicly — TechCrunch
- Anthropic releases Mythos-like AI model to the public, Claude Fable 5 — CNBC
- Anthropic’s new model is Mythos on a leash — CyberScoop
- Anthropic just released public Mythos-class AI model called Claude Fable — 9to5Mac
- Claude Mythos Preview — Anthropic (red team)